
O objetivo desse artigo é mostrar uma série de aprendizados e dicas de alguém precisou escalar meia dúzia de funções lambda criadas pra pequenas automações de infraestrutura, tarefas agendadas, resposta automática pra alertas até equipes grandes de produtos inteiramente construídos utilizando Serverless por meio de FaaS com AWS Lambda, mas essas dicas podem ser absorvidas por qualquer um que seja o vendor que você estiver utilizando.
Sempre tive curiosidade pela adoção de tecnologias Serverless na resolução de problemas, e desde o primeiro contato sempre busquei formas de trazer a utilização desse tipo de tecnologia pro meu dia a dia. Aqui vai o meu compiladão com as principais dicas que eu gostaria que alguém tivesse me dado quando comecei a desbravar esse tipo de arquitetura.
1. Use um orquestrador, e se possível o Serverless Framework
A primeira apresentação que tive com o AWS Lambda me mostrou uma abordagem simplista de “gerar zipzinhos” com seu código, selecionar um runtime da sua linguagem, e botar pra rodar. Depois criar um endpointzinho na mão no API Gateway e integrar naquela Lambda e pá. Tenho um Hello World “sem servidor”. A primeira dúvida, de quem veio de equipes de desenvolvimento de ERP e SaaS é “Beleza, mas não da pra usar no dia a dia”. Com 10, 20, 30 funções, em uma equipe mais dinâmica de desenvolvimento essa rotina do build do “zipzinho” e configurações manuais se torna impraticável.
Utilizar um orquestrador via CLI faz com que seja possível integrar seu deploy, multistage, testes a qualquer pipeline de entrega contínua, e ele cobre muita configuração manual que você teria que executar conforme sua aplicação e equipe escalam.
Existem vários tipos de orquestradores, o meu favorito é a figurinha carimbada do assunto, o Serverless Framework.
O Serverless Framework cobre vários vendors de mercado como Google Cloud, Azure, IBM, Fn e o que nós usamos, o saudoso AWS Lambda.
Página do Serverless Framework
2. Use/Crie um boilerplate de projeto
Quando você trabalha sozinho assuntos como organização, padronização e reaproveitamento de código não são coisas tão importantes assim. Quando você precisa escalar esse tipo de tecnologia pra um ou mais times de desenvolvimento, é necessário existir um consenso de padrões e boas práticas, e também de um centralizador de bibliotecas.
Afinal é inviável ficar replicando modificações incrementais, correções bugs em 20, 30 versões diferentes da mesma biblioteca. Por isso crie uma estruturação minima de código para seus projetos. Nossa proposta de organização e estruturação está pública e open source. Esse boilerplate é utilizado desde os pequenos até os grandes projetos, e ele também está lá no README oficial do Serverless Framework do Github.
Link para o Boilerplate que criamos
3. Testes, eles precisam existir aqui também
Mais um ponto crucial da velha escola que precisamos adotar dentro desse novo paradigma. Aplicações construídas sobre arquiteturas Serverless são naturalmente muito difíceis de serem testados por normalmente consumirem muitos recursos vendor como filas do SQS, Streams do Kinesis, Tabelas do Dynamo, Buckets do S3 e etc.
No caso, utilizamos 100% de NodeJS em nossos projetos, e aproveitamos a maravilhosa stack de testes que o Javascript nos provê via comunidade. No caso utilizamos:
Também é possível utilizar o o Lab da Hapi caso seja de sua preferência.
O teste de funções lambda seguem um padrão até que simples. Normalmente a AWS injeta uma função de callback , na qual normalmente usamos para encerrar a execução da mesma. O segredo é que vamos injetar essa função de callback nas funções que queremos testar e fazer os assertations do retorno.

4. Seu Cloud rodando local
É necessário que seus desenvolvedores consigam simular localmente alguns recursos especificos da núvem que você está utilizando. No nosso caso, usamos em peso vários serviços fornecidos pela AWS. Para diminuir a diferença entre os ambiente de desenvolvimento local com os ambientes de homolação, produção e etc, será necessário conseguir utilizar alguns desses principais serviços localmente.
Adotamos algumas estratégias matadoras pra resolver esse problema;
- O Plugin Serverless Offline;
- Muito Docker;
- Plugins e mais plugins da comunidade;
Atraves do serverless-offline, plugin do Serverless Framework, conseguimos realizar chamadas de API localmente, diretamente pela porta 3000
- dherault/serverless-offiline - Emulate AWS λ and API Gateway locally when developing your Serverless project
- msfidelis/serverless-offline-sqs-esmq - Simple SQS and ESMQ plugin for Serverless Framework ⚡️ ⚡️
- ajmath/serverless-offline-scheduler - Integrates with serverless-offline to run scheduled lambdas locally. Can also be run independently
- svdgraaf/serverless-pseudo-parameters - Use CloudFormation Pseudo Parameters in your Serverless project
Rodamos o Serverless Offline via Docker também. Tentamos conteinerizar tanto o ambiente do serverless offline quanto as dependências de infraestrutura mockada da AWS.
Separamos nossos outros serviços da AWS emulados localmente em outros containers, quando isso cresce demais, utilizamos o Localstack. Até o numero de containers virar um problema, gostamos de separar tudo.
Segue alguns recursos que usamos pra mockar localmente a infra da AWS:
- localstack/localstack - A fully functional local AWS cloud stack. Develop and test your cloud & Serverless apps offline!
- 99xt/serverless-dynamodb-local - Serverless Dynamodb Local Plugin - Allows to run dynamodb locally for serverless
- ar90n/serverless-s3-local - Serverless s3 local plugin
- softwaremill/elasticmq - Message queueing system with an actor-based Scala and Amazon SQS-compatible interfaces. Runs stand-alone or embedded.
5. Aplicação de verdade, roda em VPC
Um dos critérios mais importantes para criar aplicações de verdade, robustas e seguras na AWS, será necessário ir além do básico dentro das configurações de rede. Ou seja, precisaremos gastar um tempo projetando a rede interna do nossa aplicação.
Segue algumas dicas importantes:
- Escolha pelo menos duas zonas de disponibilidade. Isso vai garantir uma redundância caso o serviço do lambda venha a falhar em alguma delas.
- Cada zona de disponibilidade deverá ter no mínimo uma subnet publica e uma privada para rodar a aplicação. Isso garante o tráfego pra internet e o isolamento de execução das funções da DMZ.
- As lambdas deverão ser configuradas para rodar somente nas subnets privadas. Sempre.
- Crie mais uma subnet em cada AZ sem acesso a internet para fazer deploy dos bancos de dados SQL, Redis, Memcached, Elasticsearch e derivados. Isso te garante uma camada a mais de segurança e isolamento de recursos.
- Crie um NAT Gateway com IP fixo em uma das subnets públicas, e faça o roteamento das Route Tables de todo o tráfego das subnets privadas para o NAT Gateway — Isso é importante, porque assim todas as requisições vão sair pra internet sempre com o mesmo IP. Uma hora ou outra você vai se deparar com algum vendor, parceiro e etc que vai necessitar de um IP fixo do seu lado pra alguma liberação, e vai te poupar um estresse do tipo "COMO QUE EU VOU FAZER LAMBDA TER IP FIXO, OS CARA TA DOIDO". É possível, e mais fácil resolver isso logo de cara.
- Crie sempre suas subnets privadas com uma máscara de subnet baixa. Isso vai garantir uma quantidade significativa de IP's disponiveis. A quantidade de lambdas em execução vai se limitar pelo número de IP's disponiveis entre as subnets indicadas pra elas rodarem. Normalmente as subnets de aplicação, fazemos deploy com a notação /20, isso nos dá em torno de 4094 IP's em cada subnet para execução de lambdas. Da pra escalar bastante. Nas auxiliares fazemos o deploy com a notação padrão /24 mesmo.
ATENÇÃO: Colocando funções dentro de VPC's, você vai precisar declarar seus security groups e subnets no arquivo .yml. Você pode adicionar alguma latência ao retirar as funções do cold warm up pela necessidade de uma interface ENI ser alocada no container que vai estar invocando a função.
6. Segurança na AWS
Padrões de Firewall, monitoramento e segurança são necessários pra garantir a estabilidade de uma aplicação, esteja seguindo qualquer padrão quer seja. Existem várias soluções de firewall e CDN no mercado pra que você consiga colocar na frente da sua API ou aplicação. No nosso caso adotamos uma arquitetura bacana utilizando CloudFront na frente da nossa API.
Mas CloudFront?? CDN? Cache?? Na frente de uma API??
Sim. Utilizamos o Cloudfront, mas sem cachear nada, passando todo o conteúdo para a origem. Mas pra que isso? Simples! O AWS WAF.
Até o presente momento, ainda não é possível anexar regras do AWS WAF diretamente do API Gateway em todas as regiões, mais especificamente sa-east-1 (São Paulo). Dos nossos serviços, só anexamos diretamente no que está rodando na Virginia. Nas demais localizações aproveitamos essa arquitetura. Por enquanto.
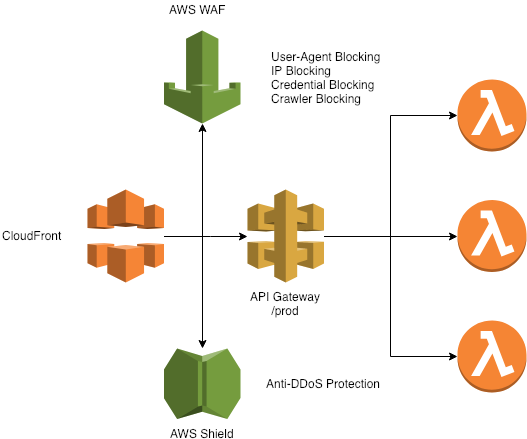
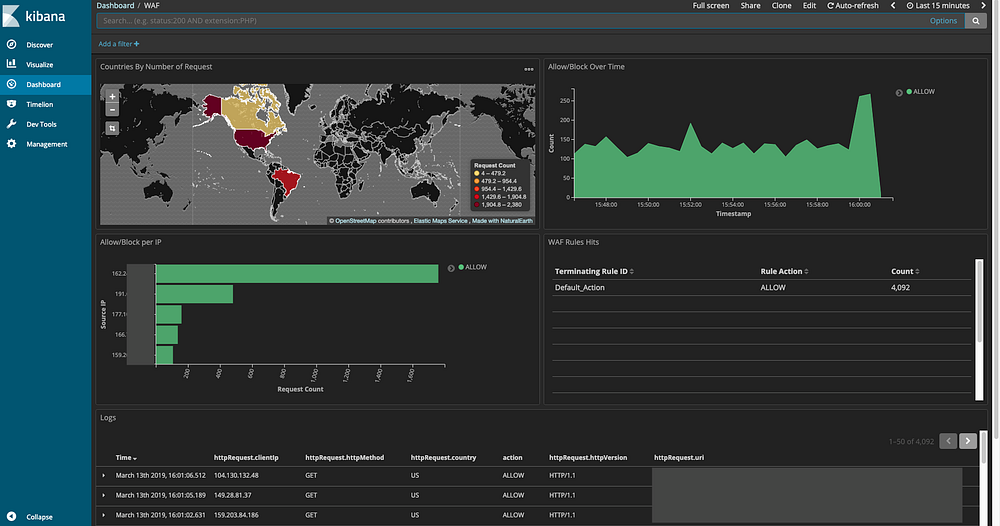
Normalmente redirecionamos os logs das nossas regras do WAF pra um Stream do Kinesis e em seguida direcionamos para um cluster de Elasticsearch pra análise e monitoramento.
7. Bancos SQL são possíveis!
Na maioria dos exemplos que encontramos sobre Serverless, em 200% só se fala no querido DynamoDB. Mas essa realidade de persistência de dados pode ser estendida ao bom e velho SQL se necessário, abrindo o leque pra bancos MySQL, MariaDB, PostgreSQL, SQL Server, Oracle e etc. Porém são necessários alguns pontos de atenção:
- Sua aplicação deverá estar rodando dentro de um contexto de VPC;
- Será necessário anexar uma security group a execução das suas funções lambda;
- Esse security group dos runtimes deverão estar autorizados na porta do serviço do banco de dados, seja ele RDS ou não. Caso esteja utilizando um banco de dados em algum outro lugar, autorize o IP de saída da sua rede. Lembra que eu te falei que vai ser importante a qualquer momento?
- Cuidado com o pool de conexões, talvez dê ruim e seu banco venha a ficar indisponível dependendo do throughput das suas funções lambda.
8. Bancos NoSQL, Memory Cache, Storage são seus melhores amigos
Faça muito uso de recursos como o DynamoDB pra escalar escrita e leitura em lotes. Mas cuidado!
Use muito memory cache como clusters de Redis e Memcached para tirar carga dos bancos de dados. No caso do DynamoDB, pode ficar caro escalar muito Write / Read com muita frequência, e os bancos SQL, bom, da velha escola, eles são sempre o gargalo mais chato.
Então use a abuse da velha escola de arquitetura pra esse novo paradigma. Muita coisa pode ser reaproveitada e até melhorada nesse novo contexto de desenvolvimento.
9. Entregue tudo por uma Pipeline
Mesmo com um orquestrador, ainda existem problemas a serem lidados com escala de times e deploys diários. O ideal é manter o produto sendo entregue sempre por uma pipeline de entrega continua, onde você vai garantir a estabilidade e qualidade o seu código serverless pra qualquer stage que você estiver trabalhando.
O que podemos incluir numa pipeline pra ajudar a garantir os padrões de qualidade que eu necessito no meu projeto em Serverless? Segue uma listinha:
- Testes unitários e de integração (Mocha, Chai, Lab)
- Syntax Check & Design Patterns (jslint, jshint, standard)
- Documentação & GMUD (Pra processos mais burocráticos)
- Segurança (npm audit, SourceClear, retire.js, arachni)
Você pode utilizar o que você quiser, existem ótimas opções de mercado e Open Source como CircleCI, CodeShip, Jenkins e etc. Aqui entregamos todos os nosso produtos e funções auxiliares por meio da stack do CodePipeline da AWS. Motivo? Podemos entregar desde o projeto mais simples até os mais complexos com a mesma ferramenta. Normalmente adicionamos os steps de build em um arquivo buildspec.yml.
Segue um exemplo:
Utilizamos nosso orquestrador via CLI pra automatizar uma entrega de código continua em produção.
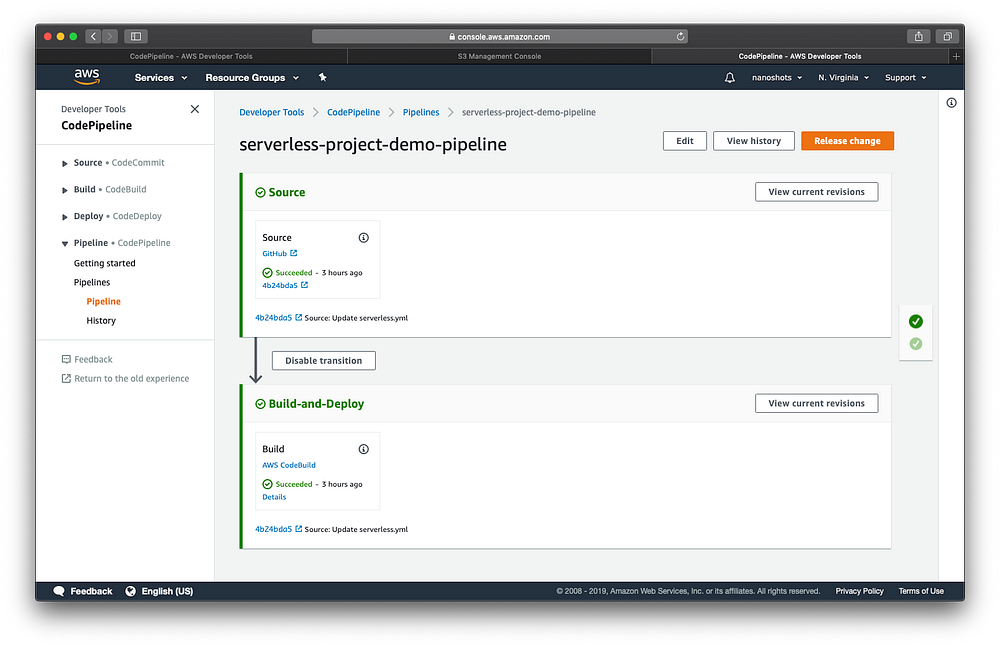
Disponibilizamos também nossa pipeline genérica pra escalar projetos Serverless em produção, é bem simples de usar e evoluir a complexidade dos projetos caso necessário. Segue em anexo.
- msfidelis/serverless-pipeline - Pipeline to build, test and deploy Serverless Framework Projects with CodeBuild and CodePipeline on AWS using Terraform. ⚡️ 🚀 ⚡️ 🚀
10. Promova flexibilidade de ambientes
Da mesma forma que costumamos criar diversos stages de desenvolvimento pra ter testes mais fiéis antes de subir uma feature pra uma gama maior de clientes em aplicações mais convencionais, as vezes será necessário aplicar isso no nosso processo de desenvolvimento da mesma forma. Utilizando um orquestrador como o Serverless Framework, fazer isso fica mais fácil. Basta adaptar a sua pipeline de integração e ser feliz!
serverless deploy -v --stage homologacao11. Variáveis de ambiente
Aproveitando a dica anterior, você vai precisar modificar sem duvida alguma algumas configurações entre seu ambiente de stage, homolog, prod, nem que seja um apontamento de bancos, credenciais de ambientes de produção pra homologação, limites, prefixos e uma série de coisas que a gente só toma ciência depois que nossa aplicação cresce.
Fazemos um load no serverless.yml dinamicamente com as variáveis de ambiente do stage em contexto, que passamos durante o deploy, no caso:
serverless deploy -v --stage developIremos carregar o arquivo configs/develop.yml com as variáveis desse ambiente. Um truque bem simples e legal.
O AWS lambda oferece recursos de variáveis de ambiente e conseguimos trabalhar bem com esse recurso utilizando o Serverless Framework, porém as vezes não é muito seguro trabalhar com tokens, senhas, chaves de criptografia e deixar isso diretamente no painel AWS Lambda. Minha sugestão é utilizar a biblioteca node-config ou o saudoso dotenv.
- lorenwest/node-config - node.js application configuration file
- motdotla/dotenv - Loads environment variables from .env for nodejs projects.
12. Workers e o processamento desacoplado
É possível escalar Workers utilizando AWS Lambda, porém isso nem sempre é tão simples dependendo do caso. Podemos criar uma estrutura básica de worker que escuta uma fila do SQS, ou um Redis, Kafka, RabbitMQ e etc, porém como vocês já devem saber nessa altura do campeonato, devemos trabalhar com timeout e memória durante a execução de uma função lambda. No momento que escrevo este post, o máximo permitido no tempo de execução é 15 minutos.
Minha pra evitar o timeout durante o processamento de muitos itens de forma assíncrona, minha sugestão é sempre dividir o processamento de um lote de itens em lotes menores, e encaminhar esses lotes menores pra diferentes funções lambdas executarem em paralelo.
- Uma lambda é encarregada de puxar os lotes de mensagens de uma fila qualquer;
- Essa lambda divide os itens em pequenos lotes de 5, 10, 20, 40 itens, que seja;
- Essa lambda é encarregada de evocar o processamento de uma nova lambda responsável por executar cada um desses pequenos lotes de itens;
13. Monitore tudo, mas tudo mesmo
Aplicações Serverless herdam um pouco do cenário de microserviços tanto no aspecto positivo quanto no negativo, principalmente em questão de monitoramento. Ainda não existe nenhuma solução consolidada de APM pra serviços Serverless. Com o crescimento da aplicação, problemas vão surgir, e você vai se dar conta de que as métricas básicas que são provisionadas de cara, como Invocations, numero de erros, concorrência e afins não vão mais fazer tanto sentido.
Existem algumas iniciativas do New Relic e Dashbird pra isso, mas quando o seu tracing precisar ser mais detalhado, você ainda vai precisar correr pra soluções mais granulares e vai perceber que são as mesmas “feijão com arroz”, como o CloudWatch e o X-Ray pra monitoramento distribuido.
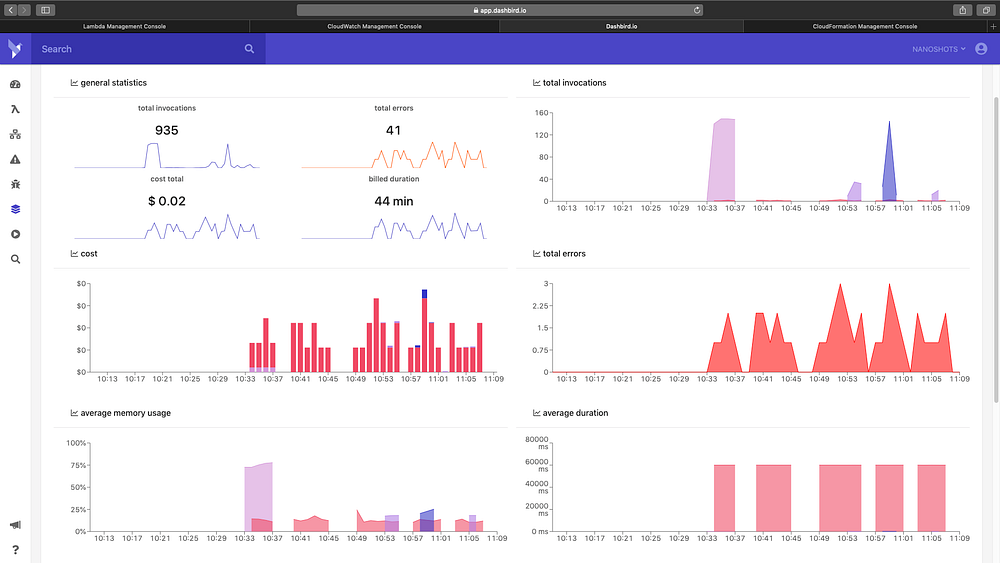
Segue minhas alternativas
- New Relic (Infraestucture Integration & Serverless APM)
- Dashboard
- Cloudwatch Logs + Dashboard
- X-Ray Tracing
Append: Limite de 200 Resources nos Templates do CloudFormation
Conforme seu projeto crescer em numero de endpoints, de resources de infraestrutura e eventos, você pode acabar se deparando com o seguinte erro:
Error --------------------------------------------------
The CloudFormation template is invalid: Template format error: Number of resources, 208, is greater than maximum allowed, 200
For debugging logs, run again after setting the "SLS_DEBUG=*" environment variable.
A dica quanto a isso é fazer o split dessa stack em várias outras no mesmo script de Cloudformation. Pra isso eu recomendo o uso do plugin serverless-plugin-split-stacks.
Você vai precisa apenas declarar algumas configurações no campo custom do seu serverless.yml selecionando a forma de como você deseja splittar seu projeto dentro do Cloudformation.
custom:
splitStacks:
perFunction: true
perType: true
perGroupFunction: false
stackConcurrency: 5
resourceConcurrency: 10
Resumo
- Não é tão simples quanto te disseram;
- Serverless não mata o DevOps, muito pelo contrário, torna muito mais necessária a adoção das práticas e cultura;
- Todos os anos de aprendizado sobre qualidade de software podem ser reaproveitados;
- Nem tudo precisa ser reinventado, existe um legado de ouro deixado por outros paradigmas de desenvolvimento;
- O desenvolvedor precisa sim trabalhar localmente;
- A segurança deve ser levada em consideração;
- O multistage é uma realidade;
- Ainda é necessário utilizar pipelines de entrega pra escalar seu time;
- Ainda são necessárias ferramentas pra garantir a qualidade do código;
- Qualidade do processo de desenvolvimento continua o mesmo;
- Monitore tudo, mas tudo mesmo!
Espero ter ajudado pessoal!
Link migrado do meu perfil do Medium.










Parabéns pela publicação!
ResponderExcluir